Ruby 2.7
- Released at: Dec 25, 2019 (NEWS file)
- Status (as of Dec 26, 2025): 2.7.8 is EOL
- This document first published: Dec 27, 2019
- Last change to this document: Dec 26, 2025
Highlights
Ruby 2.7 is a last major release before 3.0¹, so it introduces several important changes, larger in scale than previous releases (and also a bit lean on a “just nice to have” features side). Be prepared!
- Pattern matching
- “Real” keyword argument
- Numbered block parameters
- Beginless range
Enumerator.produceGC.compact- Large update of IRB
- Serious cleanup of the standard library
¹There is a possibility 2.8 will also be released, but in any case, Christmas release of 2020 is promised to be Ruby 3.0.
Language
Pattern matching
Pattern matching is a completely new and experimental feature for structural value checking against patterns, and local variable binding. As it is new and huge, we’ll not try to cover the feature here and just send the reader to the official documentation. Just a small example:
require 'open-uri'
require 'json'
data = URI.open('https://api.github.com/repos/ruby/ruby/pulls').read
.then { |body| JSON.parse(body, symbolize_names: true) }
data in [{user: {login:}, title:, created_at:}, *] # match array of hashes, with deep matching inside first hash
[login, title, created_at] # matched values bound to local variables
# => ["zverok", "Add pattern matching documentation", "2019-12-25T18:42:03Z"]
- Follow-ups:
- Pattern matching became a stable (non-experimental) feature, and its power expanded signficantly in 3.0;
- Then, it became even more flexible in 3.1;
- In 3.2, several core and standard library classes (
MatchData,Time,Date,DateTime) became deconstructible.
Keyword argument-related changes
Ruby 2.7 introduced a lot of changes towards more consistent keyword arguments processing. Fortunately, the official Ruby site has a full description of those changes, with examples, justifications and relationships of features with each other.
Therefore here we’ll just list the changes for the sake of completeness of this changelog.
- Warnings (would be errors in 3.0) for implicit conversion of the last argument-hash to keyword arguments, and vice versa;
Module#ruby2_keywordsandProc#ruby2_keywordsmethods to mark method and proc as not warning when the last argument is used as keyword one (to provide backward- and forward-compatible way of defining “delegating all” methods);- “Forward all arguments” syntax:
(...) - Non-
Symbolkeys are allowed in keyword arguments unpacking; **nilsyntax in method definition to explicitly mark method that doesn’t accept keywords (and can’t be called with a hash without curly braces);-
empty hash splat doesn’t pass empty hash as a positional argument.
- Follow-up: Warnings became errors in 3.0, and some edge cases were fixed.
Numbered block parameters
In block without explicitly specified parameters, variables _1 through _9 can be used to reference parameters.
- Reason: It is one of the approaches to make short blocks DRY-er and easier to read. E.g. in
filenames.each { |f| File.read(f) }, repetition offand extra syntax needed for it can be considered an unnecessary verbosity, soeach { File.read(_1) }could be now used instead. - Discussion: The feature was discussed for a long time, syntax and semantics was changed several times on the road to 2.7:
- Feature #4475 (initial discussion, started 9 years ago, and finished with accepting of
@0—@9), - Misc #15723 (change to
_0—_9), - Bug #16178 (dropping of
_0, and changing semantics of_1)
- Feature #4475 (initial discussion, started 9 years ago, and finished with accepting of
- Documentation: Proc#Numbered parameters
- Code:
# Simplest usage: [10, 20, 30].map { _1**2 } # => [100, 400, 900] # Multiple block parameters can be accessed as subsequent numbers [10, 20, 30].zip([40, 50, 60], [70, 80, 90]).map { _1 + _2 + _3 } # => [120, 150, 180] # If only _1 is used for multi-argument block, it contains all arguments [10, 20, 30].zip([40, 50, 60], [70, 80, 90]).map { _1.join(',') } # => ["10,40,70", "20,50,80", "30,60,90"] # If the block has explicit parameters, numbered one is SyntaxError [10, 20, 30].map { |x| _1**2 } # SyntaxError ((irb):1: ordinary parameter is defined) # Outside the block, usage is warned: _1 = 'test' # warning: `_1' is reserved as numbered parameter # But after that, _1 references local variable: [10].each { p _1 } # prints "test" # Numbered parameters are reflected in Proc's parameters and arity p = proc { _1 + _2 } l = lambda { _1 + _2 } p.parameters # => [[:opt, :_1], [:opt, :_2]] p.arity # => 2 l.parameters # => [[:req, :_1], [:req, :_2]] l.arity # => 2 # Nested blocks with numbered parameters are not allowed: %w[test me].each { _1.each_char { p _1 } } # SyntaxError (numbered parameter is already used in outer block here) # %w[test me].each { _1.each_char { p _1 } } # ^~ - Follow-ups:
Beginless range
In addition to endless range in Ruby 2.6: (start..), Ruby 2.7 introduces beginless one: (..end).
- Reason: Array slicing (initial justification for endless ranges) turned out to be not the only usage for semi-open ranges. Another ones, like
case/grep, DSLs and constants andComparable#clamp, can gain from the symmetry of “range without end”/”range without beginning”. - Discussion: Feature #14799
- Documentation:
doc/syntax/literals.rdoc#Ranges - Code:
# Usage examples %w[a b c][..1] # same as [0..1], not really useful case creation_time when ...1.year.ago then 'ancient' when 1.year.ago...1.month.ago then 'old' when 1.month.ago...1.day.ago then 'recent' when 1.day.ago... then 'new' end users.map(&:age).any?(...18) # Properties: r = ..10 r.begin # => nil r.count # TypeError (can't iterate from NilClass), same with any other Enumerable methods r.size # => Infinity - Notes:
- Slightly “a-grammatical” name (“beginless” instead of “beginningless”) is due to the fact that it is a range literally lacking
beginproperty. - Unfortunately, parser can not always handle beginless range without the help of the parentheses:
(1..10).grep ..5 # ArgumentError (wrong number of arguments (given 0, expected 1)) # ...because it is in fact parsed as ((1..10).grep()..5), e.g. range from grep results to 5This may seem an esoteric problem, but it becomes less esoteric in DSLs. For example in RubySpec, one would like to write:
ruby_version ..'1.9' do # some tests for old Ruby end…but the only way is
ruby_version(..'1.9') do # some tests for old Ruby end
- Slightly “a-grammatical” name (“beginless” instead of “beginningless”) is due to the fact that it is a range literally lacking
Other syntax changes
- Comments between
.foocalls are now allowed:(1..20).select(&:odd?) # This was not possible in 2.6 .map { |x| x**2 } # => [1, 9, 25, 49, 81, 121, 169, 225, 289, 361] - Quotes (if exist) in HERE-documents should be on the same line as document start:
<<"EOS " # This had been warned since 2.4; Now it raises a SyntaxError EOS -
Modifier
rescueparsing change (multiple assignment now consistent with singular):a = raise rescue 1 # => 1 a # => 1 in Ruby 2.6 and 2.7 a, b = raise rescue [1, 2] # => [1, 2] # 2.6 a # => nil b # => nil # The statement parsed as: (a, b = raise) rescue [1, 2] # 2.7 a # => 1 b # => 2 # The statement parsed as: a, b = (raise rescue [1, 2])
Warnings/deprecations
Some older or accidental features are deprecated on the road to 3.0 and currently produce warnings.
Note that Ruby 2.7 also introduced a way to turn off only some categories of warnings, for example, only deprecation ones.
yieldin singleton class syntax (was inconsistent with local variables accessibility). Discussion: Feature #15575.def foo x = 1 class << Object.new p x # NameError (undefined local variable or method) -- enclosing scope NOT accessible yield # calls block passed to foo, implying enclosing scope IS accessible # In Ruby 2.7: warning: `yield' in class syntax will not be supported from Ruby 3.0. end end foo { p :ok }$;and$,global variables (Perl ancestry: defaultsplitandjoinseparators):$; = '???' # warning: non-nil $; will be deprecated 'foo???bar'.split # warning: $; is set to non-nil value # => ["foo", "bar"] $, = '###' # warning: non-nil $, will be deprecated %w[foo bar].join # warning: $, is set to non-nil value "foo###bar"- Implicit block capturing in
procandlambda:def foo proc.call # here the block passed to method is implicitly captured by proc end foo { puts "Hello" } # warning: Capturing the given block using Kernel#proc is deprecated; use `&block` instead # still prints "Hello" - Contrastingly, the flip-flop syntax deprecation, introduced in 2.6, is reverted. It turned out that for brevity in text-processing scrips (including one-liners run as
ruby -e "print <something>") the feature, however esoteric it may seem, has a justified usage.- Discussion: Feature #5400.
- Documentation:
doc/syntax/control_expressions.rdoc#Flip-Flop - Code:
# Imagine we are working with some data file where real data starts with "<<<"" line and end with ">>>>" File.each_line('data.txt', chomp: true).filter_map { |ln| ln if ln == '<<<'..ln == '>>>' } # => gets lines starting from <<<, and ending with >>>. # The condition "flips on" when the first part is true, and then "flips off" when the second is true # Flip-flop-less version would be something like this (with the difference: it ignores last >>>): lines.drop_while { |ln| ln != '<<<' }.take_while { |ln| ln != '>>>' }- Note: The BIG difference with “enumerator-based” filtering, which makes flip-flops useful in complicated data processing, is that enumerator’s can’t express multiple “ons and offs” (imagine file has several
<<< ... >>>blocks and try to solve the task without flip-flops).
- Note: The BIG difference with “enumerator-based” filtering, which makes flip-flops useful in complicated data processing, is that enumerator’s can’t express multiple “ons and offs” (imagine file has several
“Safe” and “taint” concepts are deprecated in general
The concepts of marking objects as "tainted" (unsafe, came from the outside) and “untaint” them after the check, is for a long time ignored by most of the libraries. $SAFE constant, trying to limit “unsafe” calls when set to higher values, is considered a fundamentally flawed method and documented so since Ruby 2.0. At the same time, as the “official” security features, subtle bugs in implementation of $SAFE and tainting have caused lot of “vulnerability reports” and added maintenance burden.
- Discussion: Feature #16131
self.<private_method>
Calling a private method with a literal self as the receiver is now allowed.
- Reason: “
anything.methodis always disallowed for private methods” seemed like a simple and unambiguous rule, but produced some ugly edge cases (for example,self.foo = somethingfor privateattr_accessorwas allowed). It turned out “allow literalself.” makes things much clearer. - Discussion: Feature #11297, Feature #16123
- Documentation:
doc/syntax/modules_and_classes.rdoc#Visibility - Code:
class A def update self.a = 42 # works even in Ruby 2.6, because there was no other way to call private setter self.a += 42 # "private method `a' called" in 2.6, works in 2.7 self + 42 # "private method `+' called" in 2.6, works in 2.7 x = self x.a = 42 # "private method `a=' called" even in 2.7, not a literal self end private attr_accessor :a def +(other) puts "+ called" end end
Refinements in #method/#instance_method
- Discussion: Feature #15373
- Code:
module StringExt refine String do def wrap(what) before, after = self.split('|', 2) "#{before}#{what}#{after}" end end end using StringExt '<<|>>'.method(:wrap) # => #<Method: String(#<refinement:String@StringExt>)#wrap(what) refinement_test.rb:3> %w[test me please].map(&'<<|>>'.method(:wrap)) # 2.6: undefined method `wrap' for class `String' # 2.7: => ["<<test>>", "<<me>>", "<<please>>"]
Core classes and modules
Better Method#inspect
Method#inspect now shows method’s arguments and source location (if available).
- Reason: As there are more code style approaches that operate
Methodobjects, making them better identifiable and informative seemed necessary. - Discussion: Feature #14145
- Documentation:
Method#inspect - Code:
p CSV.method(:read) # Ruby 2.6: # => #<Method: CSV.read> # Ruby 2.7: # => #<Method: CSV.read(path, **options) <...>/lib/ruby/2.7.0/csv.rb:714> # For methods defined in C, path and param names aren't available, but at least generic signature is: [].method(:at) # => #<Method: Array#at(_)> # Convention: unknown param name is displayed as _, param has default value -- as ... def m(a, b=nil, *c, d:, e: nil, **rest, &block) end p method(:m) #=> #<Method: m(a, b=..., *c, d:, e: ..., **rest, &block) ...skip...> - Notes:
- while enhancing
Method#inspect,Proc’s string representation also changed for consistency: now object id separated from location by ` ` (for easier copy-pasting). Discussion: Feature #16101p(proc {}) # Ruby 2.6: # => #<Proc:0x000055e4d93f2708@(irb):13> # Ruby 2.7: # => #<Proc:0x000055e4d93f2708 (irb):13> - The same is related to
Thread. Discussion: Feature #16412p(Thread.new {}) # Ruby 2.6: # => #<Thread:0x000055be3d72fcd0@(irb):2 run> # Ruby 2.7: # => #<Thread:0x0000561efab16560 (irb):2 run>
- while enhancing
UnboundMethod#bind_call
Binds UnboundMethod to a receiver and calls it. Semantically equivalent to unbound_method.bind(receiver).call(arguments), but doesn’t produce intermediate Method object (which bind does).
- Reason: The technique of storing unbound methods and binding them later is used in some metaprogramming-heavy code to robustly use “original” implementation. For example:
MODULE_NAME = Module.instance_method(:name) class Customer def self.name "<Customer Model>" end end Customer.name # => "<Customer Model>" MODULE_NAME.bind_call(Customer) # => "Customer"In such cases (for example, code reloaders), overhead of producing new
Methodobject on eachbind().callis pretty significant, andbind_callallows to avoid it. - Discussion: Feature #15955
- Documentation:
UnboundMethod#bind_call
Module
#const_source_location
Returns the location of the first definition of the specified constant.
- Discussion: Feature #10771
- Documentation:
Module#const_source_location - Code:
# Assuming test.rb: class A C1 = 1 end module M C2 = 2 end class B < A include M C3 = 3 end class A # continuation of A definition end p B.const_source_location('C3') # => ["test.rb", 11] p B.const_source_location('C2') # => ["test.rb", 6] p B.const_source_location('C1') # => ["test.rb", 2] p B.const_source_location('C4') # => nil -- constant is not defined p B.const_source_location('C2', false) # => nil -- don't lookup in ancestors p Object.const_source_location('B') # => ["test.rb", 9] p Object.const_source_location('A') # => ["test.rb", 1] -- note it is first entry, not "continuation" p B.const_source_location('A') # => ["test.rb", 1] -- because Object is in ancestors p M.const_source_location('A') # => ["test.rb", 1] -- Object is not ancestor, but additionally checked for modules p Object.const_source_location('A::C1') # => ["test.rb", 2] -- nesting is supported p Object.const_source_location('String') # => [] -- constant is defined in C code
#autoload?: inherit argument
- Reason: More granular checking “if something is marked to be autoloaded directly or through ancestry chain” is necessary for advanced code reloaders (requested by author of zeitwerk).
- Discussion: Feature #15777
- Documentation:
Module#autoload? - Code:
class Parent autoload :Feature1, 'feature1.rb' end module Mixin autoload :Feature2, 'feature2.rb' end class Child < Parent include Mixin end Child.autoload?(:Feature1) # => "feature1.rb" Child.autoload?(:Feature1, false) # => nil Child.autoload?(:Feature2) # => "feature2.rb" Child.autoload?(:Feature2, false) # => nil
Comparable#clamp with Range
Comparable#clamp now can accept Range as its only argument, including beginless and endless ranges.
- Reason: First, ranges can be seen as more “natural” to specify a range of acceptable values. Second, with introduction of beginless and endless ranges,
#clampnow can be used for one-sided value limitation, too. - Discussion: Feature #14784
- Documentation:
Comparable#clamp - Code:
123.clamp(0..100) # => 100 -20.clamp(0..100) # => 0 15.clamp(0..100) # => 15 # With semi-open ranges: 123.clamp(150..) # => 150 123.clamp(..120) # => 120 # Range with excluding end is not allowed 123.clamp(0...150) # ArgumentError (cannot clamp with an exclusive range) # Old two-argument form still works: 123.clamp(0, 150) # => 123
Integer[] with range
Allows to get several bits at once.
- Discussion: Feature #8842
- Documentation:
Integer#[] - Code:
# 4---0 # v v 0b10101001[0..4] # => 9 0b10101001[0..4].to_s(2) # => "1001"
Complex#<=>
Complex#<=>(other) now returns nil if the number has imaginary part, and behaves like Numeric#<=> if it does not.
- Reason: Method
#<=>was explicitly undefined inComplexto underline the fact that linear order of complex numbers can’t be established, but it was inconsistent with most of the other objects implementations (which returnnilfor impossible/incompatible comparison instead of raising) - Discussion: Bug #15857
- Documentation:
Complex#<=> - Code:
1 + 2i <=> 1 # => nil 1 + 2i <=> 1 + 2i # => nil, even if numbers are equal 1 + 0i <=> 2 # => -1
Strings, symbols and regexps
- Unicode version: 12.1
- New encodigs: CESU-8
Core methods returning frozen strings
Several core methods now return frozen, deduplicated String instead of generating it every time the string is requested.
- Reason: Avoiding allocations of new strings for each
#to_sof primitive objects can save dramatic amounts of memory. - Discussion: Feature #16150
- Affected methods:
NilClass#to_s,TrueClass#to_s,FalseClass#to_s,Module#name - Code:
# Ruby 2.6 true.to_s.frozen? # => false 3.times.map { true.to_s.object_id } # => [47224710953060, 47224710953040, 47224710953000] -- every time new object # Ruby 2.7 true.to_s.frozen? # => true 3.times.map { true.to_s.object_id } # => [180, 180, 180] -- frozen special string - Notes:
- Change introduces incompatibility for the code looking like:
value = true # ... buffer = value.to_s buffer << ' -- received' # Ruby 2.6: "true -- received" # Ruby 2.7: FrozenError (can't modify frozen String: "true") - The same change was proposed for
Symbol#to_s(and could’ve been a dramatic improvement in some kinds of code), but the change turned out to be too disruptive.
- Change introduces incompatibility for the code looking like:
- Follow-up: Instead of freezin
Symbol#to_s, new methodSymbol#namereturning frozen string was introduced in 3.0.
Symbol#start_with? and #end_with?
- Reason: Symbol was once thought as “just immutable names” with any of “string-y” operations not making sense for them, but as
Symbol#matchwas always present, andSymbol#match?implemented in 2.4, it turns out that other content inspection methods are also useful. - Discussion: Feature #16348
- Documentation:
Symbol#end_with?,Symbol#start_with? - Code:
:table_name.end_with?('name', 'value') # => true :table_name.start_with?('table', 'index') # => true # Somewhat confusingly, Symbol arguments are not supported :table_name.end_with?(:name, 'value') # TypeError (no implicit conversion of Symbol into String)
Time
#floor and #ceil
Rounds Time’s nanoseconds down or up to a specified number of digits (0 by default, e.g. round to whole seconds).
- Reason: Rounding of nanoseconds important in a test code, when comparing
Timeinstances from a different sources (stored in DB, passed through third-party libraries, etc.). Having better control on truncation comparing toTime#round(which existed since 1.9.2) - Discussion: Feature #15653 (floor, Japanese), Feature #15772 (ceil)
- Documentation:
Time#floor,Time#ceil - Code:
t = Time.utc(2019, 12, 24, 5, 43, 25.8765432r) t.floor # => 2019-12-24 05:43:25 UTC t.floor(2) # => 2019-12-24 05:43:25.87 UTC t.ceil # => 2019-12-24 05:43:26 UTC t.ceil(2) # => 2019-12-24 05:43:25.88 UTC
#inspect includes subseconds
- Reason: Losing subseconds in
#inspectalways made debugging and testing harder, producing test failures like “Expected: 2019-12-21 16:11:08 +0200, got 2019-12-21 16:11:08 +0200” (which are visually the same, but one of them, probably going through some serialization or DB storage, has different value for subseconds). - Discussion: Feature #15958
- Documentation:
Time#inspect - Code:
t = Time.utc(2019, 12, 24, 5, 43, 25.8765432r) p t # Ruby 2.6: prints "2019-12-24 05:43:25 UTC" # Ruby 2.7: prints "2019-12-24 05:43:25.8765432 UTC" puts t # always prints "2019-12-24 05:43:25 UTC" # Note that sometimes representation falls back to Rational fractions: t2 = Time.utc(2019,12,31, 23,59,59) + 1.4 p t2 # => 2020-01-01 00:00:00 900719925474099/2251799813685248 UTC # That's when subseconds can't be represented as 9-digit whole number: (t.subsec * 10**9).to_f # => 876543200.0 (t2.subsec * 10**9).to_f # => 399999999.99999994
Enumerables and collections
Enumerable#filter_map
Transforms elements of enumerable with provided block, and drops falsy results, in one pass.
- Reason: Filter suitable elements, then process them somehow is a common flow of sequence processing, yet with
filter { ... }.map { ... }additional intermediateArrayis produced, which is not always desirable. Also, some processing can indicate “can’t be processed” by returningfalseornil, which requires code likemap { ... }.compact(to dropnils) ormap { ... }.select(:itself)(to drop all falsy values). - Discussion: Feature #15323
- Documentation:
Enumerable#filter_map - Code:
(1..10).filter_map { |i| i**2 if i.even? } # => [4, 16, 36, 64, 100] # imagine method constantize() returning false if string can't be converted to # a proper constant name constant_names = %w[foo 123 _ bar baz/test].filter_map { |str| constantize(str) } # => ['Foo', 'Bar'] # Without block, returns Enumerator: %w[foo bar baz test].filter_map .with_index { |str, i| str.capitalize if i.even? } # => ["Foo", "Baz"]
Enumerable#tally
Counts unique objects in the enumerable and returns hash of {object => count}.
- Discussion: Feature #11076
- Documentation:
Enumerable#tally - Code:
%w[Ruby Python Ruby Perl Python Ruby].tally # => {"Ruby"=>3, "Python"=>2, "Perl"=>1} - Notes:
#tallyfollows#to_hintuitions (and uses it underneath): objects are considered same if they have the same#hash; orders of keys corresponds to order of appearance in sequence; first object in sequence becomes the key- Additional block argument, or, alternatively, additional method
tally_by(&block)was proposed in the same ticket to allow code like(1..10).tally_by(&:even?) # => {true => 5, false => 5}…but was not accepted yet.
- Follow-up: In Ruby 3.1,
#tally(hash)was introduced to accumulate statistics from several collections into a single hash.
Enumerator.produce
Produces infinite enumerator by calling provided block and passing its result to subsequent block call.
- Reason:
.produceallows to convert anywhile-alike orloop-alike loops into enumerators, making possible to work with them in a Ruby-idiomaticEnumerablestyle. - Discussion: Feature #14781
- Documentation: Enumerator.produce
- Code:
require 'date' # Before: while cycle to search next tuesday: d = Date.today while !d.tuesday d += 1 end # After: enumerator: Enumerator.produce(Date.today, &:succ) # => enumerator of infinitely increasing dates .find(&:tuesday?) require 'strscan' PATTERN = %r{\d+|[-/+*]} scanner = StringScanner.new('7+38/6') # Before: while cycle to implement simple lexer: result = result << scanner.scan(PATTERN) while !scanner.eos? # After: achieving the same with enumerator (which can be passed to other methods to process): Enumerator.produce { scanner.scan(PATTERN) }.slice_after { scanner.eos? }.first # => ["7", "+", "38", "/", "6"] # Raising StopIteration allows to stop the iteration: ancestors = Enumerator.produce(node) { |prev| prev.parent or raise StopIteration } # => enumerator enclosing_section = ancestors.find { |n| n.type == :section } # => :section node or nil # If the initial value is passed, it is an argument to first block call, and yielded as a first # value of enumerator Enumerator.produce(1) { |prev| p "PREVIOUS: #{prev}"; prev + 1 }.take(3) # "PREVIOUS: 1" # "PREVIOUS: 2" # => [1, 2, 3] # If the initial value is not passed, first block call receives `nil`, and the block's first result # is yielded as a first value of enumerator Enumerator.produce { |prev| p "PREVIOUS: #{prev.inspect}"; (prev || 0) + 1 }.take(3) # "PREVIOUS: nil" # "PREVIOUS: 1" # "PREVIOUS: 2" # => [1, 2, 3]
Enumerator::Lazy#eager
Converts lazy enumerator back to eager one.
- Reason: When working with large data sequences, lazy enumerators are useful tools to not produce intermediate array on each step. But some data consuming methods expect to receive enumerators that would really return data from methods like
take_whileand not just add them to pipeline. - Discussion: Feature #15901
- Documentation:
Enumerator::Lazy#eager - Code:
# Imagine we read very large data file: lines = File.open('data.csv') .each_line .lazy .map { |ln| ln.sub(/\#.+$/, '').strip } # remove "comments" .reject(&:empty?) # drop empty lines p lines # => #<Enumerator::Lazy: ....> # Now, we want to consume just "headers" from this CSV, and pass the rest of enumerator # into the other methods. # This code: headers = lines.take_while { |ln| ln.start_with?('$$$') } # ...will just produce another lazy enumerator, with `take_while` chained to pipeline. # Now, this: lines = lines.eager # makes the enumerator eager, but (unlike `#force`) doesn't consume it yet p lines # => #<Enumerator: #<Enumerator::Lazy: ...>:each> # consumes only several first lines and returns array of headers headers = lines.take_while { |ln| ln.start_with?('$$$') } # => [array, of, header, lines] # now we can pass `lines` to methods that expect take_while/take and other similar methods to # consume enumerator partially and return arrays
Enumerator::Yielder#to_proc
- Reason: When constructing the enumerator, value yielding is frequently delegated to other methods, which accept blocks. Before the change, it was inconvenient to delegate.
- Discussion: Feature #15618
- Documentation:
Enumerator::Yielder#to_proc - Code:
# Construct a enumerator which will pass all lines from all files from some folder: # Before the change: all_lines = Enumerator.new { |y| # y is Yielder object here Dir.glob("*.rb") { |file| File.open(file) { |f| f.each_line { |ln| y << ln } } } } # After the change: all_lines = Enumerator.new { |y| # y is Yielder object here Dir.glob("*.rb") { |file| File.open(file) { |f| f.each_line(&y) } } }
Array#intersection
Like Array#union and #difference, added in 2.6 as a explicitly-named and accepting multiple arguments alternatives for #| and #-, the new method is alternative for #&.
- Discussion: Feature #16155
- Documentation:
Array#intersection - Code:
['Ruby', 'Python', 'Perl'].intersection(['Ruby', 'Diamond', 'Perl'], ['Ruby', 'Nikole', 'Kate']) # => ["Ruby"] ['Ruby', 'Python', 'Perl'].intersection # => ["Ruby", "Python", "Perl"] - Follow-up: Ruby 3.1 introduced
Array#intersect?predicate.
ObjectSpace::WeakMap#[]= now accepts non-GC-able objects
- Reason:
ObjectSpace::WeakMap(theHashvariety that doesn’t hold its contents from being garbage-collected) is mostly thought, as the name implies, as an “internal” thing. But turns out it can have some legitimate usages in a regular code, for example, implementing flexible caching (cache which “auto-cleans” on garbage collection). But before this change, keys forWeakMapwasn’t allowed to be non-GC-able (for example, numbers and symbols), which prohibits some interesting usages. - Discussion: Feature #16035
- Documentation:
WeakMap#[]= - Code:
map = ObjectSpace::WeakMap.new map[1] = Object.new # Ruby 2.6: ArgumentError (cannot define finalizer for Integer) # Ruby 2.7: Writes the map successfully map[1] # => #<Object:0x0000561ea70ec3d0> GC.start map[1] # => nil -- value successfully collected, even if key was not GC-able - Follow-ups: 3.3: A new class
ObjectSpace::WeakKeyMapintroduced, more suitable for common use-cases of a “weak mapping.” It only has garbage-collectable keys.
Fiber#raise
Raises exception inside the resumed Fiber.
- Reason: Ability to raise an exception inside Fiber makes control passing abilities more feature-complete.
- Discussion: Feature #10344
- Documentation:
Fiber#raise - Code:
f = Fiber.new { Enumerator.produce { Fiber.yield } # Infinite yielding enumerator, breaks on StopIteration .to_a.join(', ') } f.resume f.resume 1 f.resume 2 f.resume 3 f.raise StopIteration # => "1, 2, 3" - Notes:
Fiber#raisehas the same call sequence asKernel#raiseand can be called without any arguments (RuntimeErroris empty message is raised), with string (RuntimeErrorwith provided message is raised), exception class and (optional) message, or instance of the exception. - Follow-up: In 4.0,
Fiber#raisesignature was adjusted (to match the changed signature ofKernel#raisethat allows to providecause:of the exception).
Range
#=== for String
In 2.6, Range#=== was changed to use #cover? underneath, but not for String. This was fixed.
- Discussion: Bug #15449
- Documentation:
Range#=== - Code:
case '2.6.5' when '2.4'..'2.7' 'matches' else 'nope :(' end # => "nope :(" in 2.6, "matches" in 2.7
#minmax implementation change
Range#minmax switched to returning Range#end instead of iterating through Range to get maximum value.
- Reason:
Range#minmaxwas previously implemented inEnumerable, giving some inconsistencies with separate#minand#maxin edge cases like:(1..).max #=> RangeError (cannot get the maximum of endless range) (1..).minmax #=> Runs forever, trying to iterate while it is not exhausted ("a".."aa").max #=> "aa" ("a".."aa").minmax #=> ["a","z"] -- iteration through range goes till "aa", but then "aa" < "z", so "z" is maximum - Discussion: Feature #15807
- Documentation:
Range#minmax - Code:
(1..).minmax # => RangeError (cannot get the maximum of endless range) (1..Float::INFINITY).minmax # => [1, Infinity] ("a".."aa").minmax # => ["a", "aa"] - Note: As can be seen in String example, sometimes
#minmax(as well as#max) can yield unexpected result (the value which is in fact not the maximum of all Range contents). This is true for value types with ambiguous order definition (“zz” is between “a” and “aa” in enumeration, yet still larger than “aa”).
Filesystem and IO
IO#set_encoding_by_bom
Auto-sets encoding to UTF-8 if byte-order mark is present in the stream.
- Discussion: Feature #15210
- Documentation:
IO#set_encoding_by_bom - Code:
File.write("tmp/bom.txt", "\u{FEFF}мама") ios = File.open("tmp/bom.txt", "rb") ios.binmode? # => true ios.external_encoding # => #<Encoding:ASCII-8BIT> ios.set_encoding_by_bom # => #<Encoding:UTF-8> ios.external_encoding # => #<Encoding:UTF-8> ios.read # => "мама" File.write("tmp/nobom.txt", "мама") ios = File.open("tmp/nobom.txt", "rb") ios.set_encoding_by_bom # => nil ios.external_encoding # => #<Encoding:ASCII-8BIT> ios.read # => "\xD0\xBC\xD0\xB0\xD0\xBC\xD0\xB0" # The method raises in non-binary-mode streams, or if encoding already set: File.open("tmp/bom.txt", "r").set_encoding_by_bom # ArgumentError (ASCII incompatible encoding needs binmode) File.open("tmp/bom.txt", "rb", encoding: 'Windows-1251').set_encoding_by_bom # ArgumentError (encoding is set to Windows-1251 already)
Dir.glob and Dir.[] not allow \0-separated patterns
- Discussion: Feature #14643
- Documentation:
Dir.glob - Code:
Dir.glob("*.rb\0*.md") # 2.6: # warning: use glob patterns list instead of nul-separated patterns # => ["2.5.md", "History.md", "README.md" ... # 2.7 # ArgumentError (nul-separated glob pattern is deprecated) # Proper alternative, works in 2.7 and earlier versions: Dir.glob(["*.rb", "*.md"]) # => ["2.5.md", "History.md", "README.md" ...
File.extname returns a "." string at a name ending with a dot.
- Reason: It is argued that
File.basename(str, '.*') + File.extname(str)should always reconstruct the full name, but it was not the case for names likeimage. - Discussion: Bug #15267
- Documentation: File.extname
- Code:
filename = "image." [File.basename(filename, ".*"), File.extname(filename)] # 2.6: => ["image", ""] -- the dot is lost # 2.7: => ["image", "."]
Exceptions
FrozenError: receiver argument
In 2.6 several exception class constructors were enhanced so the user code could create them providing context, now FrozenError also got this functionality.
- Discussion: Feature #15751
- Documentation:
FrozenError#new - Code:
class AlwaysFrozenHash < Hash # ... def update!(*) raise FrozenError.new("I am frozen!", receiver: self) end end - Notice:
<Exception>.newsyntax is the only way to pass new arguments, this would not work:raise FrozenError, "I am frozen!", receiver: self
Interpreter internals
$LOAD_PATH.resolve_feature_path
resolve_feature_path was introduced in Ruby 2.6 as RubyVM method, now it is singleton method of $LOAD_PATH global variable.
- Reason: It was argued that
RubyVMshould contain code specific for particular Ruby implementation (e.g. it can be different between CRuby/JRuby/TruffleRuby/etc.), whileresolve_feature_pathis a generic feature that should behave consistently between Ruby implementations. - Discussion: Feature #15903
- Documentation: As it turns, documenting global’s singleton method is not easy. So it is just mentioned at
doc/globals.rdoc - Code:
$LOAD_PATH.resolve_feature_path('net/http') # => [:rb, "/home/zverok/.rvm/rubies/ruby-head/lib/ruby/2.7.0/net/http.rb"] - Notes: As method was just moved, for details of
resolve_feature_pathbehavior, see 2.6 changelog’s entry (with the exception for what described in the next section)
resolve_feature_path behavior for loaded features fixed
In 2.6, resolve_feature_path returned false instead of the path for already loaded libraries. That was fixed.
- Discussion: Feature #15230
- Documentation: — (see above)
- Code:
# Ruby 2.6: RubyVM.resolve_feature_path('net/http') # => [:rb, "<...>/lib/ruby/2.6.0/net/http.rb"] require 'net/http' RubyVM.resolve_feature_path('net/http') # => [:rb, false] # Ruby 2.7: $LOAD_PATH.resolve_feature_path('net/http') # => [:rb, "<...>/lib/ruby/2.7.0/net/http.rb"] require 'net/http' $LOAD_PATH.resolve_feature_path('net/http') # => [:rb, "<...>/lib/ruby/2.7.0/net/http.rb"] - Follow-up: In Ruby 3.1, the behavior for not found files was adjusted too (to return
nilinstead of raising).
GC.compact
Ruby 2.7 ships with an improved GC, which allows to manually defragment memory.
- Reason: After some time of application running, creating objects and garbage collecting them, the memory becomes “fragmented”: there are a large holes of unused memory between actual living objects. The new methods meant to be called between, say, spanning of the new processes/workers, potentially making current process using less memory.
- Discussion: Feature #15626
- Documentation:
GC.compact - Note: This changelog author’s understanding of GC and compacting is far from perfect, so the explanations are sparse. Unfortunately, the new feature is not thoroughly documented yet, so the best guess for understanding the change is reading “discussion” link above. The PRs (to the changelog and/or to the Ruby’s main documentation) are welcome.
Warning::[] and ::[]=
Allows to emit/suppress separate categories of warnings.
- Reason: 2.7 introduced a lot of new deprecations (especially around keyword arguments, there can easily be thousands), and one “really experimental” feature (pattern matching), which emits warning about its experimental status on every use. To make working with older code, or experimenting with new features, less tiresome, the ability to turn warnings on and off per category was introduced.
- Discussion: Feature #16345 (deprecated warnings), Feature #16420 (experimental warnings)
- Documentation:
Warning::[],Warning::[]= - Code:
{a: 1} in {a:} # warning: Pattern matching is experimental, and the behavior may change in future versions of Ruby! Warning[:experimental] = false {a: 1} in {a:} # ...no warning issued... def old_method(hash, **kwargs) end old_method(foo: 'bar') # warning: Passing the keyword argument as the last hash parameter is deprecated Warning[:deprecated] = false old_method(foo: 'bar') # ...no warning... # The current settings can be inspected: Warning[:deprecated] # => false # ...and changed back: Warning[:deprecated] = true old_method(foo: 'bar') # warning: Passing the keyword argument as the last hash parameter is deprecated - Notes:
- The only existing categories currently are
:deprecated(covers all deprecations) and:experimental(as of 2.7, covers only pattern matching) - Note that turning off
:deprecatedwarning will also mute the warning of features which was deprecated explicitly in your code, for example withModule#deprecate_constantclass HTTP NOT_FOUND = Exception.new deprecate_constant :NOT_FOUND end HTTP::NOT_FOUND # warning: constant HTTP::NOT_FOUND is deprecated Warning[:deprecated] = false HTTP::NOT_FOUND # ...no warning issued... - Another way to turn on and off separate categories of warnings is passing
-W:(no-)<category>flag to ruby interpreter, e.g.-W:no-experimentalmeans “no warnings when using experimental features”.
- The only existing categories currently are
- Follow-ups:
Standard library
Datesupports new Japanese era in parsing and rendering dates (genericDate.parseand.jisx0301/#jisx0301). Discussion: Feature #15742DelegateClass()accepts a block to define delegates behavior on-the-fly.Pathname.globpasses third argument, if provided, toDir.glob, allowing to specifybase:for globbing.Pathname()method doesn’t duplicates argument, if it was already aPathnameOptionParsernow uses “Did you mean?” feature. Discussion: Feature #16256.require 'optparse' OptionParser.new do |opts| opts.on('-t', '--task NAME') end.parse!(%w[--tsak build]) # OptionParser::InvalidOption (invalid option: --tsak) # Did you mean? task
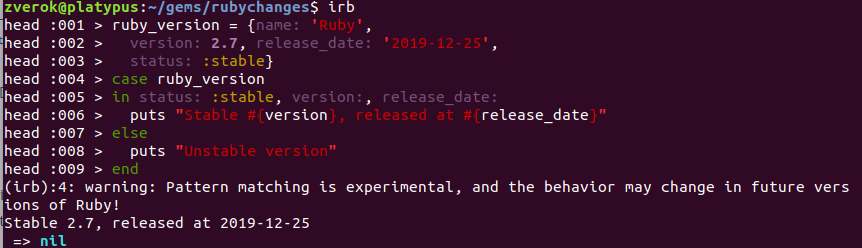
Large IRB update
IRB, Ruby’s default console, received its biggest update in years. Now it supports multiline editing, syntax highlighting of input and (some) output, auto-indentation and other modern console behavior. Small demonstration screenshot:
Network and web
Net::HTTP#start: new optional keyword parameteripaddr:, and#ipaddr=setter allows to set the address for the connection manually. Discussion: Feature #5180.open-urilibrary: 2 versions after the safer alias was added, usingKernel#openfinally became deprecated, andURI.openbecame the main library’s interface. Discussion: Misc #15893require 'open-uri' open('https://ruby-lang.org') # warning: calling URI.open via Kernel#open is deprecated, call URI.open directly or use URI#open URI.open('https://ruby-lang.org') # => okNet::FTP#featuresto check available features, andNet::FTP#optionto enable/disable each of them. Discussion: Feature #15964.ftp = Net::FTP.new('speedtest.tele2.net') # TELE2's open FTP for speed tests ftp.features # => ["EPRT", "EPSV", "MDTM", "PASV", "REST STREAM", "SIZE", "TVFS"]Net::IMAPnow has Server Name Indication (SNI) support. Discussion: Feature #15594
Large updated libraries
- Bundler 2.1.2: Changes
- CSV 3.1.2: Changes
- JSON 2.3.0: Changes (lacks 2.3.0)
- Racc 1.4.15: (no changelog available)
- REXML 3.2.3: Changes
- RSS 0.2.8: Changes
- RubyGems 3.1.2: Changes
- StringScanner 1.0.3: Changes
Standard library contents change
New libraries
- Reline is a newly introduced readline-compatible pure Ruby line editing library. It is behind the new IRB’s magic.
Libraries promoted to default gems
stdgems.org project has a nice explanations of default and bundled gems concepts, as well as a list of currently gemified libraries.
“For the rest of us” this means libraries development extracted into separate GitHub repositories, and they are just packaged with main Ruby before release. It means you can do issue/PR to any of them independently, without going through more tough development process of the core Ruby.
Libraries extracted in 2.7:
- Published at rubygems.org
- Extracted to default gems, but not published on rubygems.org yet:
Libraries excluded from the standard library
Unsupported and lesser used libraries removed from the standard library, and now can be installed as a separate gems.
- CMath
- Scanf
- Shell
- Synchronizer
- ThreadsWait
- profile.rb aka
Profiler__: removed completely. No one maintains it since Ruby 2.0.0 (note it exists on GitHub and even has.gemspecthere but is not published to rubygems.org)
Follow-up: 34 (!) more libraries gemified in 3.0, and 3 more just dropped from the standard library (including infamous WEBrick).